


Initialising ...
Initialising ...
Initialising ...
Initialising ...
Initialising ...
Initialising ...
Initialising ...
市原 潔*; 横川 三津夫; 蕪木 英雄
JAERI-Data/Code 96-012, 43 Pages, 1996/03
 JAERI-Data-Code-96-012.pdf:1.26MB
JAERI-Data-Code-96-012.pdf:1.26MB
3次元圧縮性ナビエ・ストークス方程式のうち、最も計算時間を要する圧力方程式にDOループ分割による並列化を行った。red-black SOR法による並列化されたプログラムをVPP500およびParagon上で実行した結果、両者ともスケーラビリティの低下がPE数の増加とともに現われる傾向を共通している。その原因は、VPP500の場合は通信時間の増大とベクトル化効率の2つであるのに対し、Paragonの場合は通信時間の増大のみに依存していることが判明した。また、PCG法の不完全LU分解法にred-black SOR法を適用してVPP500上で実行した時は、PE数が1の場合は反復による実行ステップ数の増加にもかかわらず高いベクトル化効率による若干の実行時間短縮が図れる。しかし、PE数が4以上では、ベクトル化効率低下が著しいため、並列化のメリットが現れにくいことが判明した。
Ali, Y.*; 伊奈 拓也*; 小野寺 直幸; 井戸村 泰宏
no journal, ,
圧力ポアソン方程式のクリロフ部分空間法ソルバは大規模多相CFDシミュレーションにおいて全計算コストの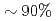 を占める。このポアソンソルバを加速するためにブロックヤコビ(BJ)前処理付きチェビシェフ基底共役勾配法(CBCG)ソルバをP100GPUに移植した。CBCGソルバはBJ前処理, 疎行列ベクトル積(SpMV), 非正方行列積から構成される。本研究ではスレッド・ブロック並列処理と効率的なコアレスドロードのためにBJ前処理を再設計し、非正方行列積にBatched GEMMを適用した。上記最適化により全ての主要カーネルでルーフラインに基づく理論性能のを達成し、CPUノードに比べて一桁以上のノード性能向上が得られた。
を占める。このポアソンソルバを加速するためにブロックヤコビ(BJ)前処理付きチェビシェフ基底共役勾配法(CBCG)ソルバをP100GPUに移植した。CBCGソルバはBJ前処理, 疎行列ベクトル積(SpMV), 非正方行列積から構成される。本研究ではスレッド・ブロック並列処理と効率的なコアレスドロードのためにBJ前処理を再設計し、非正方行列積にBatched GEMMを適用した。上記最適化により全ての主要カーネルでルーフラインに基づく理論性能のを達成し、CPUノードに比べて一桁以上のノード性能向上が得られた。